ComfyUI 服务配置说明
当前版本说明版本: ComfyUI Desktop v0.6.0
服务配置是在 ComfyUI Desktop 的服务端(主机端)进行配置的,在这里你可以设置 ComfyUI 的局域网访问设置,一些运行的精度设置,以及一些缓存设置等等,由于对应的内容翻译自英文,可能存在一些菜单内容与实际语言设置内容不符,请以实际界面语言为准。
注意:在局域网内其它设备访问时将无法修改服务器配置
在 Portable 版本中,请使用在 .bat 文件中设置 -listen 来设置局域网访问
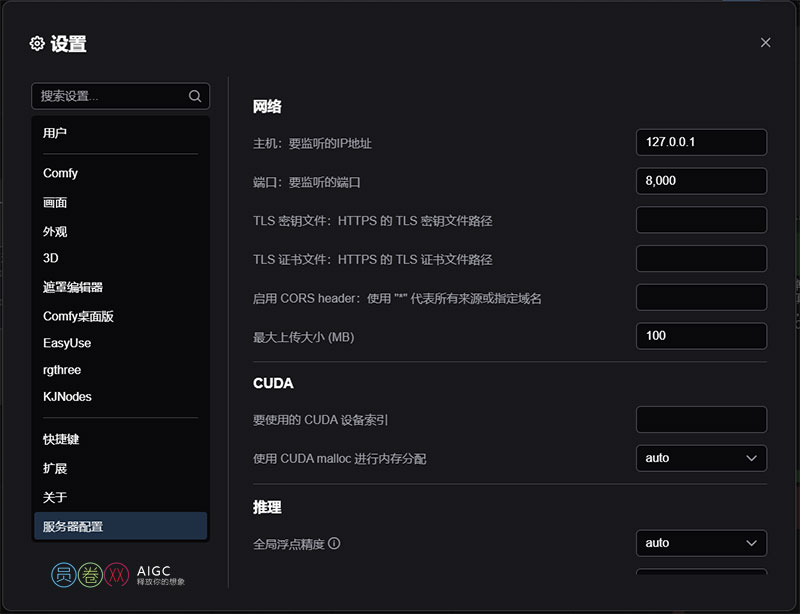
一、网络
- 监听地址 (listen)
功能:设置服务器监听的 IP 地址。通常保持默认即可。
默认值:127.0.0.1(只允许主机本地访问)
端口 (port)
功能:设置服务器监听的端口号。确保该端口未被其他应用占用。
默认值:8000(就像家里的门牌号,一般不需要修改,只有在软件冲突时候需要修改)
TLS 密钥文件 (tls-keyfile) 和 TLS 证书文件 (tls-certfile)
功能:用于设置 HTTPS 的安全连接。如果不需要 HTTPS,可以忽略。启用 CORS 头 (enable-cors-header)
功能:允许其他网站访问您的服务器。使用 ”*” 允许所有网站访问。
最大上传大小 (max-upload-size)
功能:限制上传文件的最大大小,以 MB 为单位。
默认值:100(就像行李箱的最大容量)
如果你想要设置局域网访问 ComfyUI ,那么你需要设置监听地址为 0.0.0.0,端口为 8000 或其它端口,然后通过局域网其它设备访问对应主机的局域网 IP 地址和端口即可,比如对应的局域网 IP 为 192.168.1.100,端口为 8000,那么其它设备就可以通过 http://192.168.1.100:8000 访问到 ComfyUI 了
这和早期 Portable 版本 ComfyUI 在 .bat 文件中设置 -listen 0.0.0.0 是类似的,只不过现在在 ComfyUI Desktop 中设置更加方便了
二、CUDA设置
CUDA 设备 (cuda-device)
功能:选择要使用的显卡
通俗解释:如果您有多张显卡,可以选择使用哪一张。就像有多个画室,选择在哪个画室工作
选项:0:第一张显卡 1:第二张显卡(如果有的话)null:自动选择
建议:只有一张显卡的用户保持默认即可
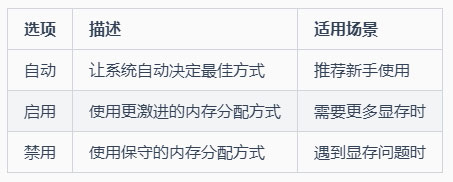
使用 CUDA malloc 进行内存分配 (cuda-malloc)
功能:决定显卡内存的分配方式
通俗解释:就像决定如何安排画室的工作空间
选项:
三、推理
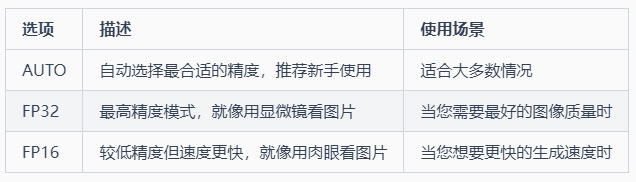
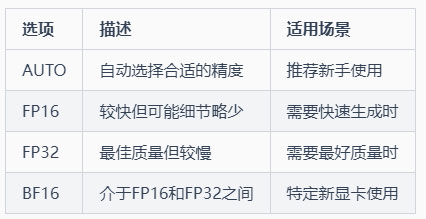
3-1 全局浮点精度 (global-precision)
功能:控制整体运算的精确度
选项:
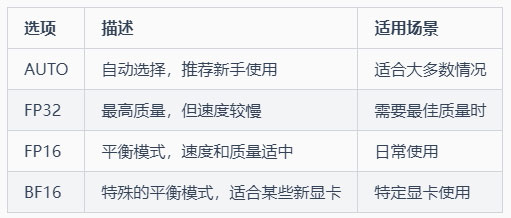
3-2 UNET 精度 (unet-precision)
功能:控制AI绘画核心部分的精确度
说明:UNET是AI绘画的”画笔”,决定了如何把您的文字变成图像
选项:
3-3 VAE 精度 (vae-precision)
功能:VAE(变分自编码器)是负责最终图像细节处理的组件,就像画家的”上色和修饰”技巧
通俗解释:决定最终图像的精细程度,就像画家最后的修饰工作细致程度
选项:
3-4 在 CPU 上运行 VAE (cpu-vae)
- 功能:让CPU来处理最终的图像修饰工作
通俗解释:就像让管家(CPU)来做画家(GPU)的收尾工作
适用场景:
-- 显卡内存不足时
-- 需要处理超大图片时
-- 显卡性能不够时
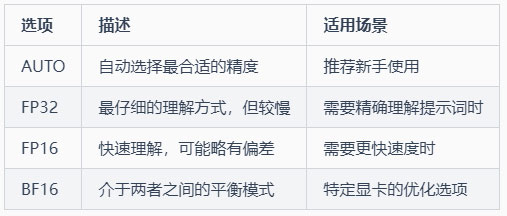
3-5 文本编码器精度 (text-encoder-precision)
功能:控制AI理解文字描述的精确程度
通俗解释:就像画家理解您的要求时的仔细程度
选项:
四、内存
4-1 强制使用 channels-last 内存格式 (force-channels-last)
功能:改变内存中图像数据的排列方式
通俗解释:就像改变画室里工具的摆放顺序,有时候可以提高效率
建议:除非您了解这个设置的影响,否则保持默认值
4-2 DirectML 设备索引 (directml)
功能:选择 DirectML 设备
通俗解释:一种特殊的绘画模式,主要用于 AMD 显卡
适用场景:使用 AMD 显卡的用户可能需要设置此项
4-3 禁用 IPEX 优化 (disable-ipex-optimize)
功能:禁用 IPEX 优化。通常不需要更改。
默认值:false
4-4 禁用智能内存管理 (disable-smart-memory)
功能:禁用智能内存管理。通常不需要更改。
默认值:false
五、预览设置
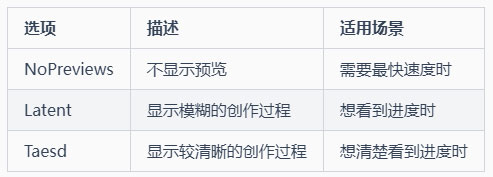
5-1 预览方法 (preview-method)
功能:控制生成过程中的预览方式
通俗解释:就像是否要看到画家的创作过程
选项:
5-2 预览图像大小 (preview-size)
功能:设置预览窗口的大小
通俗解释:就像决定草稿的大小
建议值:
-- 一般使用:512
-- 性能不足时:256
-- 性能充足时:可以设置更大
六、缓存
6-1 使用经典缓存系统 (cache-classic)
功能:使用传统的缓存管理方式
通俗解释:就像画家按固定方式整理画具和素材
适用场景:
– 系统内存充足时
– 需要稳定性能时
– 建议:除非遇到内存问题,否则保持默认值
6-2 使用 LRU 缓存 (cache-lru)
功能:设置最近使用的数据缓存量
通俗解释:就像规定画家只保留最近用过的工具和颜料
适用场景:
– 内存有限时
– 需要平衡性能和内存使用时
建议值:
– 8GB内存:设置为2-3
– 16GB内存:设置为4-6
– 32GB及以上:设置为8-12
七、注意力设置
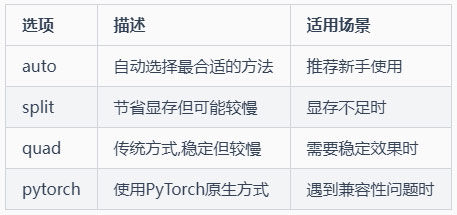
7-1 交叉注意力方法 (cross-attention-method)
功能:控制AI如何理解文字并转化为图像的方法
通俗解释:就像画家理解您的要求并在脑中构思的方式
选项:
7-2 强制注意力上升 (force-attention-upcast)
功能:强制使用更高精度处理注意力机制
通俗解释:就像让画家更仔细地思考每个细节
适用场景:当生成的图像细节不够理想时
7-3 防止注意力上升 (prevent-attention-upcast)
功能:禁止使用更高精度处理注意力机制
通俗解释:让画家快速作画而不过分关注细节
适用场景:需要更快的生成速度时
八、常规
8-1 禁用 xFormers 优化 (disable-xformers)
功能:禁用 xFormers 加速优化
通俗解释:xFormers 就像是画家的快速作画技巧,禁用它会让画家用传统方式作画
建议:除非遇到问题,否则建议保持启用(不勾选)状态
8-2 模型文件的默认哈希函数 (default-hashing-function)
功能:选择检查模型文件完整性的方法
通俗解释:就像检查画具是否完好的方式
选项:sha256 最常用的检查方式,可靠且安全
8-3 使用 pytorch 在可以时使用较慢的随机性算法
功能:在某些情况下使用更稳定但较慢的随机算法
通俗解释:就像让画家用更传统但稳定的方式来随机创作
建议:一般情况下无需启用
8-4 启用一些未经测试但可能降低质量的优化
功能:使用一些实验性的优化方法
通俗解释:尝试一些新的快速作画技巧,但可能会影响画作质量
建议:追求稳定效果时不建议启用
8-5 不将服务器输出打印到控制台
功能:不显示后台运行日志
通俗解释:让画家安静工作,不汇报每一个细节
建议:需要排查问题时建议关闭(不勾选)
8-6 禁用在文件中保存提示词数据
功能:不在生成的图片文件中保存提示词信息
通俗解释:不在画作背后记录创作的配方
适用场景:想要保持提示词私密时
8-7 禁用加载所有自定义节点
功能:禁止加载所有自定义功能模块
通俗解释:只使用基础工具,不使用额外添加的特殊工具
适用场景:想要最基础稳定的体验时
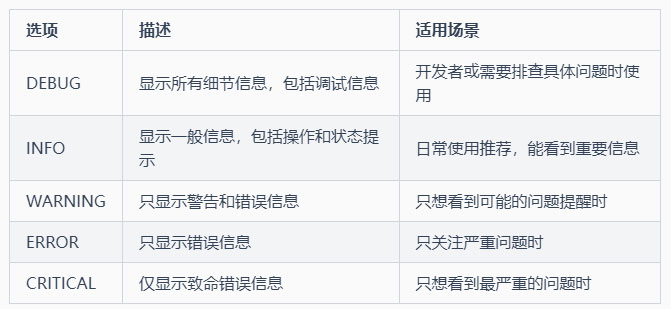
8-8 日志详细级别 (log-level)
功能:设置系统日志显示的详细程度
通俗解释:就像设置画家汇报工作的详细程度
选项:
九、目录设置
9-1 输入目录 (input-directory)
功能:设置输入文件的目录。
默认值:空字符串
9-2 输出目录 (output-directory)
功能:设置输出文件的目录。
默认值:空字符串