第三方插件
ComfyUI-Index-TTS
Index TTS Pro
Index TTS Pro
478
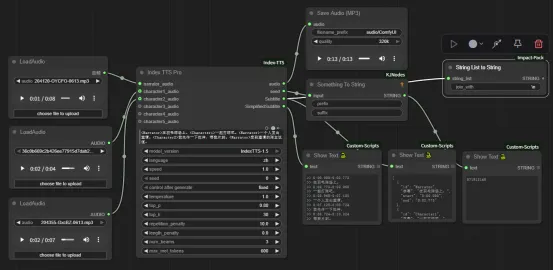
Index TTS Pro节点是ComfyUI 系统专为小说等长文本、多角色阅读设计的多角色语音合成节点。它能够:解析结构化文本(含 <Narrator> 和 <CharacterX> 标签),根据不同角色配置不同的参考音频,实现“多角色分声线朗读”,可大幅提高小说、有声书、广播剧等AIGC场景中语音生成的自动化和多样性。
节点中英文对比
按当前节点配置,分别展示中文与英文节点结构。
中文节点
Index TTS Pro
旁白音色频样本
角色1音色
角色2音色
角色3音色
角色4音色
角色5音色
合成音频
随机种子
字幕文本
简化字幕文本
英文节点
Index TTS Pro
narrator_audio
character1_audio
character2_audio
character3_audio
character4_audio
character5_audio
audio
seed
Subtitle
SimplifiedSubtitle
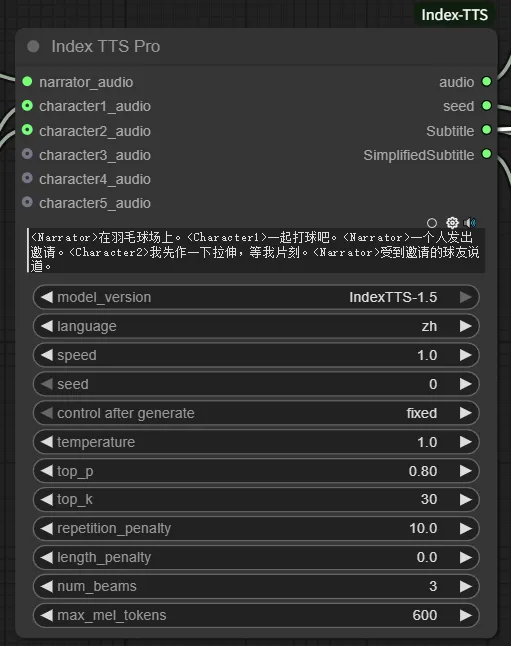
参数说明
依据当前节点关联的 `NodesItems` 数据展示输入、输出与控件说明。
输入参数
旁白音色频样本
narrator_audio
旁白/描述内容朗读所参考的音色样本(用于音色克隆,生成旁白声音)。
角色1音色
character1_audio
角色1(Character1)音色参考文件,用于模仿/还原指定角色声音。
角色2音色
character2_audio
角色2(Character1)音色参考文件,用于模仿/还原指定角色声音。
角色3音色
character3_audio
角色3(Character1)音色参考文件,用于模仿/还原指定角色声音。
角色4音色
character4_audio
角色4(Character1)音色参考文件,用于模仿/还原指定角色声音。
角色5音色
character5_audio
角色5(Character1)音色参考文件,用于模仿/还原指定角色声音。
输出参数
合成音频
audio
最终合成的多角色朗读音频(支持旁白及多角色切换)。
随机种子
seed
实际使用的随机种子。用于结果复现及溯源。
字幕文本
Subtitle
标准格式字幕文本(带时间轴,适合播放器/字幕编辑用)。
简化字幕文本
SimplifiedSubtitle
简化字幕文本(适合基础配音或同步脚本场景)。
控件参数
TTS模型版本
model_version
TTS模型版本选择(Index-TTS, IndexTTS-1.5),不同模型声音质量、风格和性能略有不同。
语言
language
输出语音的语言(auto, zh, en),默认 auto,可自动识别或强制指定。
语速
speed
语音语速控制,默认1.0,0.5~2.0(步长0.1)。1.0为正常速度,>1变快,<1变慢
随机种子
seed
随机种子,默认0,取值0~2^32-1,保持生成确定性,复现同一结果用。
控制生成多样性
temperature
控制生成多样性,默认1.0,范围0.1–1.5,数值越高音色/韵律/表现越多变,低则更一致。
采样多样化控制
top_p
采样多样化控制参数,默认0.8,范围0.0–1.0(概率累计阈值)。
采样概率
top_k
采样时仅考虑概率最高的top_k结果,默认30,1~100。
惩罚重复
repetition_penalty
惩罚重复,默认10.0,1.0~15.0,数值越高越不容易重复发音或短语。
语音长度
length_penalty
控制生成语音长度倾向,默认0,-5.0~5.0,正值倾向更短,负值倾向更长。
束宽
num_beams
搜索宽度—束宽,默认3,1~10。越高生成可靠性越强,但会变慢。
单段语音token数
max_mel_tokens
最大支持的单段语音token数,默认600,100~1500,影响生成音频长度上限。
详细说明
结合节点用途、参数和调用方式,给出更完整的说明内容。